
 — කෘතිම බුද්ධියෙන් ව්යාපාරික අනාගතයට පියවරක්")


- 1 කොටස")







Generative AI applications විසින් විශේෂ Machine Learning models වලට අපි සරළව හදුන්වනවා language models විදියට. මේවා සහය ලබාදෙනවා මිනිස් භාෂාව තේරුම් ගැනීමට හා භාවිත කරන්න මේවා භාවිත කරනවා. මේ models භාවිතා කරලා කරන්න පුලුවන් ප්රධාන කාර්යයන් අතර,
- විශාල ලිපියක් කෙටි ලිපි වලට සාරංශගත කිරීම
- වෙනස් පරිච්ඡේද කිහිපයක් සංසන්දනය කර ඒවාගේ තේරුම් අවබෝධ කරගැනීම
- කතා රචනා කිරීම, ප්රශ්න වලට පිළිතුරු සැපයීම වගේ නව තොරතුරු නිර්මාණය කරගැනීම
මේ හා සම්බන්ධ වුන පරිසරයේ, ගණිතමය අවබෝධය ඔබට මට තේරුම්ගැනීම තරමක් අපහසු වෙන්න පුලුවන්. නමුත් මේවාගේ තාක්ෂණික අවබෝධය ඔබට ලබාදෙන්නයි අපි සූදානම් වෙන්නෙ.
භාෂාව තේරුම් ගන්න භාවිතා වෙන Machine Language Models කාලයත් සමග සෑහෙන ඉදිරියට ඇවිත් තිබෙන්නෙ. බොහෝමයක් advanced language models අද වෙද්දි භාවිත කරන්නට යොමු වෙලා තිබෙන්නේ transformer architecture එක. මේ Transformer models තමන් train කරන්න පාවිච්චි කරන්නෙ අතිවිශාල text ප්රමාණයක්. මෙය මේ model එකට සහය වෙනවා වචන අතර තිබෙන අන්තර් සම්බන්ධතාවය නේරැම් ගැනීමට සහ වාක්ය නිර්මාණය කරද්දි මීලගට එන වචනය අවබෝධ කරගැනීමට.
Transformer model එකක ප්රධාන කොටස් දෙකක් තිබෙනවා. ඒ Encoder හා Decoder විදියට.
- Encoder – වචන තේරුම් අරගෙන නිවැරදි පිළිවෙලට සකස් කරනවා
- Decoder – තමා විසින් ඉගෙන ගත් දත්ත ඇසුරින් වචන හා වාක්ය නිර්මාණය කරගැනීම
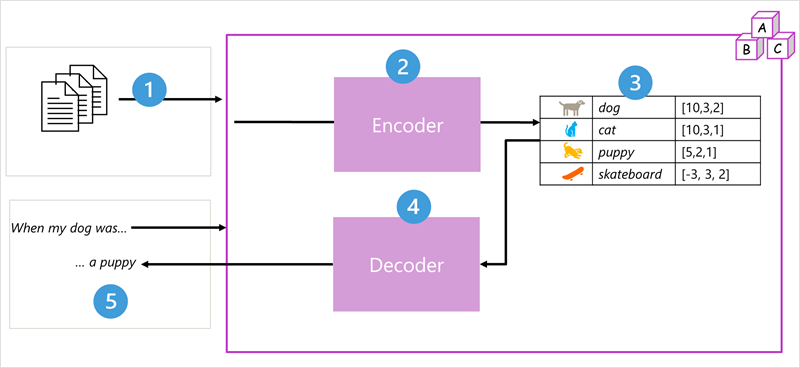
අපි දැන් මේ පියවර ටික පැහැදිලි කරගනිමු.
- Model එක train කරගැනීම – model එක train වෙන්න පාවිච්චි වෙන්නෙ අන්තර්ජාලය හා පොදු මූලාශ්ර වලින් ලබාගන්නා ලද දත්තයන්
- Tokenization – ඒ ලබාගත් තොරතුරු සියල්ලම කුඩා කොටස් වලට වෙන් කරගනු ලබනවා, tokens කියලා අපි මේවා හදුන්වනවා. Encoder එක මගින් මේ tokens process කරනවා සහ මේ process එකට අපි කියනවා attention කියලා. මේකෙන් තමයි වචන එකිනෙකට සම්බන්ධ වෙන විදිය model එක ඉගෙන ගන්නෙ.
- Embeddings – Encoder එකට පුලුවන් මේ tokens, vectors වලට හරවන්න. මේ vector කියන්නෙ numbers set එකකට. එමගින් මේවාගේ තේරුම අවබෝධ කරගන්න model එකට අවස්ථාව උදා වෙන්නෙ.
- Text Generation – decoder එකට පුලුවන් මේ Embeddings වලින් අලුත් text නිර්මාණය කරන්න.
තවත් transformer models තියෙනවා, උදාහරණයක් විදියට, BERT (by Google), GPT (by OpenAI).
Microsoft විසින් නිර්මාණය කරන ලද transformer based models ගණනාවකුත් තිබෙනවා.
1. Turing-NLG (Natural Language Generation) – Open AI වල GPT වගේම text generation අරමුණු කරගත්ත model එකක්. summarization, question-answering, සහ dialogue generation තමයි මූලික කාර්ය වෙන්නෙ.
2. Turing-Bletchley – මේක multilingual model එකක්. මූලිකවම design කරලා තිබෙන්නෙ translations සහ cross language understanding සදහා. Microsoft Translator තුල multiple languages වලට භාවිත වෙනවා.
3. DeBERTa (Decoding-enhanced BERT with Disentangled Attention) – BERT වල තවත් වැඩි දියුණු වුන version එකක් මේක. භාෂාව හදුනගන්න tasks වල ඉහළින්ම තියෙන model එකක්.
4. Phi (Small Language Model Series) – විශාලත්වයෙන් අඩු model එකක් මේක. GPT style එකේ model එක්ක compare කරද්දි ලොකු input නැතුව ඉක්මනින් ක්රියා කරවන්න මෙය නිර්මාණය කරලා තිබෙන්නෙ.
මේවා Microsoft විසින් භාවිත කරන මුලික අවස්ථා පහත දක්වලා තිබෙනවා.
- Microsoft Azure AI Services (උදා: Azure OpenAI, Azure Cognitive Services)
- Bing Search
- Microsoft Copilot ( MS Office products :Word, Excel, සහ Teams)
අපි මීලග ලිපියෙන් කතා කරමු Language Model වල වෙනස්කම් හා සමානකම් මොනවාද කියලා.







{kind=link}